Truffleを使ったSolidity開発環境の構築 + FaucetのExampleの作成
前回マスタリングイーサリアムを読んでイーサリアム周辺の話をざっくり勉強したので今度は実践。ソースコードは↓
やること
truffleとganacheを導入してローカルでsolidityをコンパイル+実行できる環境を整える。全体の流れとしては、シンプルなFaucetコントラクトを作成→ローカルのシミュレーターにデプロイ→javascriptからweb3jsを使ってABIを叩く(ABIを叩くという表現であってる?)。結構な分量になってしまった。
環境のセットアップ
何はともあれganacheをインストールする。ganacheはローカルのブロックチェーンシミュレーターで、作ったコントラクトを気軽にデプロイして試すことができる。ganache-cliというcli版も存在するのでお好きな方を。インストールが完了したら立ち上げてQuick Startを押すとシミュレーターが動き出す。
ganacheのインストールが終わったら作業用のフォルダを作成。ついでにgitも初期化しておく。
$ mkdir example1 $ cd example1 $ git init
npmで必要なパッケージをインストールする。openzeppelinは今回は利用しないがコントラクト開発で必要不可欠と言っても過言ではないのでインストール。
$ npm install web3 $ npm install -D truffle @openzeppelin/contracts mocha
ここまでで主要なツール群はインストールが終わったのでtruffleプロジェクトの初期化を行う
$ npx truffle init
実行するとディレクトリ内にcontracts, migrations, test, truffle-config.jsなどのディレクトリやファイルが作成される。truffle-config.jsにネットワークの定義が記載されているので必要に応じてganache側の設定と合わせる。デフォルトでdevelopmentと言うネットワークがコメントアウトされているので、コメントを外してポート番号もganacheのものに合わせておく。
networks: {
development: {
host: "127.0.0.1", // Localhost (default: none)
port: 8545, // Standard Ethereum port (default: none)
network_id: "*", // Any network (default: none)
}
Solidityソースコードの作成
今回は誰でもイーサの預け入れと引き出しができる口座を作成する。蛇口のように引き出せるからFaucetと呼ばれるらしい。contracts以下に新たにFaucet.solを作成し以下のようにコードを記述する。はてぶがsolidityに対応していてびっくり。
// SPDX-License-Identifier: MIT pragma solidity ^0.8.0; contract Faucet { // state variables (訳が分からない状態変数でOK?) address owner; // event類 event WithDraw(address indexed, uint amount); event Deposit(address indexed, uint amount); constructor() { // 作成者を記録 owner = msg.sender; } // 指定した額を送金する関数. soliditiyにおける通貨の基本単位はweiであることに注意 // msg.senderに対して明示的にpayableであることを指定する必要あり function withDraw(uint withdraw_amount) public { require(withdraw_amount <= 0.01 ether); // transferメソッドはaddress paybale型にしか存在しないためキャストが必要になる payable(msg.sender).transfer(withdraw_amount); emit WithDraw(msg.sender, withdraw_amount); } // Mastering Etherium出版後からsolidityの文法に変更が加わっている. // 0.6以降はデフォルトの明示的な指定が必要となるためreceive関数 // payable修飾子を付けて置けば、そのメソッドに対して送金された場合に // 送金を受け付けることができる.逆に明示的に指定しない限りコントラクトが // 送金を受け取ることができない. receive() external payable { emit Deposit(msg.sender, msg.value); } }
Faucetの概要はおおよそコメントに書いた通り。マスタリングイーサリアムのバージョン0.4と0.8では文法が変わっていたりするので注意。
コードが書けたら試しにコンパイルする。コンパイルされた結果として出力されるABIやEVMバイトコードはbuild以下にjson形式で格納される。
$ npx truffle compile
デプロイ用のマイグレーションファイルを作成する
migrations以下にデプロイ用のjsスクリプトを作成する。initしたタイミングで1_initial_migration.jsが作成されるが、それをコピーして2_deploy_contract.jsを作成する。
const Faucet = artifacts.require("Faucet"); module.exports = function (deployer) { deployer.deploy(Faucet); };
requireしているファイルがMigraionからFaucetに変更している点に注意。マイグレーションファイルが作成できたら実際にデプロイする。
$ npx truffle migrate
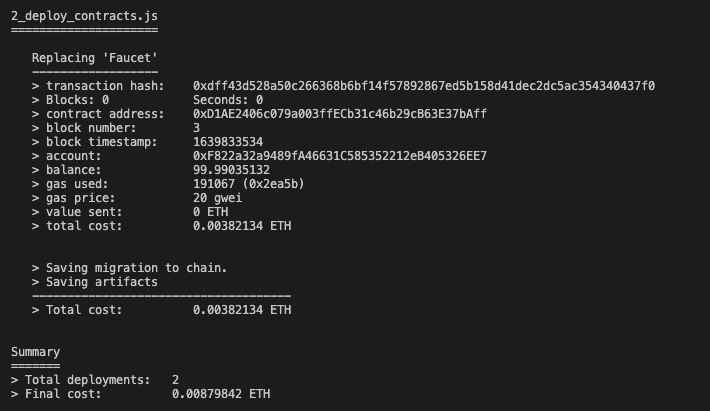
成功すれば画像のように実行結果が表示される。これで無事ganache上のテストネットワークにコントラクトがデプロイされた。
Web3jsでコントラクトを叩く
折角コントラクトを作ったので実際に利用してみる。truffleには実行補助用のコマンドexecがあるので、それを利用して動作するjavascriptコードを作成する。今回はプロジェクトルート直下にmain.jsを作成した。
web3jsを使って作成したコントラクトに入金した上で、所有する各アカウントから0.001etherづつ引き出すコードを作成した。web3jsの使い方は省略するが、ABIとアドレスを指定してContractインスタンスを作成して、methods.関数名.sendまたはmethods.関数名.callで呼び出す。どちらを使うかはブロックチェーン上のデータを変更するかどうかによって使い分ける。
const Faucet = require("./build/contracts/Faucet.json"); async function printBalance(address) { let balance = await web3.eth.getBalance(address); console.log(`Current Contract Balance: ${balance}`); } module.exports = async (callback) => { // 第1引数にデプロイしたコントラクトアドレスを指定する // truffle標準にいい感じで引数を取る方法が無さそうなのでprocess.argvから気合で取る const argv = process.argv.slice(4); const contractAddress = argv[0]; console.log(`Contract Address: ${contractAddress}`); const faucet = new web3.eth.Contract(Faucet.abi, contractAddress); // Mainとなるアカウントを指定 const accounts = await web3.eth.getAccounts(); const mainAccount = accounts[0]; // メインアカウントからFaucetに1ether預け入れ console.log("[*] Deposit 1 ether") await printBalance(contractAddress); await web3.eth.sendTransaction({ from: mainAccount, to: contractAddress, value: web3.utils.toWei("0.1", 'ether') }); await printBalance(contractAddress); console.log(""); console.log("[*] Withdraw from each account.") await printBalance(contractAddress); for(let account of accounts) { await faucet.methods.withDraw(web3.utils.toWei("0.001", "ether")).send({ from: account }); } await printBalance(contractAddress); }
実行するにはtruffle execを利用する。単位がweiのためわかりにくいがコントラクトの残高が変化していることが確認できた。
$ npx truffle exec main.js [コントラクトアドレス] Using network 'development'. Contract Address: 0xD1AE2406c079a003ffECb31c46b29cB63E37bAff [*] Deposit 1 ether Current Contract Balance: 4498000000000000000 Current Contract Balance: 4598000000000000000 [*] Withdraw from each account. Current Contract Balance: 4598000000000000000 Current Contract Balance: 4588000000000000000
おわりに
ganache上でコントラクトを実行するまでの一連の流れを紹介した。内容に不備があればコメントください。
参考
書評「マスタリングイーサリアム」
巷で流行りのNFTに乗るべく「マスタリングイーサリアム」を購入&読了したので感想。

何が書かれていて何が書かれていないのか
この本の主なトピックはイーサリアムを支える要素技術+EVMとなっている。イーサリアムは仮想通貨であると同時に、チューニング完全で単一の状態を持つ仮想マシンでもあります。この本の前半では暗号や秘密鍵等のベーシックな技術を見ていきつつ、後半ではSolidityと呼ばれる言語を利用してイーサリアム仮想マシン(EVM)で動作するプログラム(スマートコントラクト)の事例紹介が中心となっている。
逆に言うとブロックチェーン自体の技術(PoW等)の記述は殆ど無いので、その辺が知りたい人には向かないかもしれない。焦点が完全にEVM上で動作するスマートコントラクトに合っているのでトークンやNFT、スマートコントラクトのセキュリティに興味がある人にはおすすめできる内容です。
感想
知識0から読み始めたのでイーサリウムの仮想マシンとしての側面を良く知れたのは良かった。シングルスレッドかつグローバルで一つの状態を持つマシン上で誰もが任意のコードを実行できるのは凄いことでは?と終始小学生並みの感想を抱きながら読んでました。低レイヤをもっと詳しければEVMオペコードの周りとかももっと楽しんで読めるんだろうなーという感じ。
途中大事な章を読み飛ばしてスマートコントラクトって何?契約?みたいな感じで頭上に?が浮かびまくっていましたが、スマートコントラクト=イミュータブルなコンピュータプログラムというのはかなりミスリーディングな名前な気が・・・。EVMだったりSolidity関連は日本語の殆ど無いので、全体像をざっくり掴めるのはこの本の良い点だと思います。
Solidityのバージョン
イーサリウムの開発カルチャーには迅速なイノベーション、急速な進化、そして後方互換性をいくらか犠牲にしてでも将来を見越した改善を実施する意欲を特徴としています
1.10章にこのような記載があるが、本書のSolidityバージョン(0.4台)と現行のバージョン(0.8台)で乖離が大きすぎて本に乗っているコードを写経するだけだと動かないのがネック。0.6.0よりバグ防止のためfallback関数を明示的に指定しないとコンパイルが通らなくなっていたり、微妙に修正しないといけない点が多くて困る。
スマートコントラクトはイミュータブルで一度登録してしまうと変更ができないのでバグが発生しにくいように次から次に文法の修正が入っている様子。デプロイした後にバグ見つかったらどうするんだろ?
この後
折角Solidity勉強したのでEIP721読んでNFTのスマートコントラクト立ち上げてみようと思う。まずはFauset動かせるようにがんばります・・・
numpyのchoice関数を読む
javascriptは標準で重み付きのchoice関数が無いのでライブラリを探すか自分で作る必要がある。折角なのでpythonの勉強がてらnumpyのchoice関数を読んだ。
説明のため該当箇所のソースコードを引用しつつ説明を加えていく。
概観
ざっくり2つの引数(replace, p)によって挙動が変わっている。replaceは復元抽出か非復元抽出かを表していてTrueなら復元抽出になる。 pは各要素の選択確率を表していて指定されなかった場合には等確率で選択される。
replaceがTrueかFalseか×pが指定されたかされてないかの4パターンで異なるロジックが用意されていた。
復元抽出の場合
if replace: if p is not None: cdf = p.cumsum() cdf /= cdf[-1] uniform_samples = self.random(shape) idx = cdf.searchsorted(uniform_samples, side='right') # searchsorted returns a scalar idx = np.array(idx, copy=False, dtype=np.int64) else: idx = self.integers(0, pop_size, size=shape, dtype=np.int64)
まずは復元抽出の場合pは各要素の抽出確率を表す1次元配列。pが指定された場合=各要素の抽出確率が指定された場合には逆関数法的な発想で抽出を行っている。cdfが累積確率、uniform_samplesが一様分布から生成された乱数を表している。2分探索(searchsorted)を使って生成したuniform_samplesに対応する要素のインデックスをcdfから探しているだけ。
連続の場合なら逆関数法そのものだけど離散的な場合にも逆関数法と呼ぶのだろうか?少し調べるとmultinominal resampling(多項リサンプリング)という単語がヒットしたが一般的かどうかわからない。
pが指定されなかった場合には何も考えずにランダムな整数の配列を生成して、それをインデックスとして使うだけ。
非復元抽出の場合
if p is not None: if np.count_nonzero(p > 0) < size: raise ValueError("Fewer non-zero entries in p than size") n_uniq = 0 p = p.copy() found = np.zeros(shape, dtype=np.int64) flat_found = found.ravel() while n_uniq < size: x = self.random((size - n_uniq,)) if n_uniq > 0: p[flat_found[0:n_uniq]] = 0 cdf = np.cumsum(p) cdf /= cdf[-1] new = cdf.searchsorted(x, side='right') _, unique_indices = np.unique(new, return_index=True) unique_indices.sort() new = new.take(unique_indices) flat_found[n_uniq:n_uniq + new.size] = new n_uniq += new.size idx = found
次に非復元抽出の場合。多次元のインプットに対応しているせいでかなりわかりにくい。詳しくは分からないがベースのアイディアは復元抽出と同じみたい。確率の累積和を計算⇒一様分布から生成された乱数を2分探索とベースは同じ。違うのは重複した結果が含まれていた場合。newのユニークな要素を抽出して結果に足し込む+次回以降サンプルされないように当該要素がサンプルされる確率を0にする、という処理を結果が指定された要素数になるまで繰り返している様子。
非復元抽出×pが指定されなかった場合の処理は読み解けなかった。コメント欄にFloyd's Algorithmというメモがあったが検索かけてもワーシャルフロイド法しか見つからない。関係があるのだろうか。
その他
issueを調べると「もっと効率いい手法あるだろ!」というツッコミが入っている。それに対して「何回も言ってるけど効率の良い手法は殆ど入力が一次元の場合にしか対応してないだろ!numpyは多次元の入力にも対応する必要があるんじゃ!」とレスが付いてて、なるほどとなった。効率が良い手法を知りたいのであれば別のソースを読むべきだったかもしれない。 https://github.com/numpy/numpy/issues/11584
GAEのフレキシブル環境でpuppeteerを使う
prill のプリント作成機能のコア部分にはpuppeteerを使っている。GAEでpuppeteerを動かしたくて試行錯誤した結果、フレキシブル環境でカスタムコンテナを使うことで動作に成功したのでそのときのメモ。後から調べたところによると適切に設定すればスタンダード環境でもpuppeteer動かせそう。スタンダード環境のほうがお手軽だし今から試す人はそっちを使ったほうが良いかもしれない。
↓ 参考記事 github.com
TL; DR;
- GAEのフレキシブル環境ではカスタムコンテナを動かせる
- Chromeを実行可能なカスタムコンテナを作れば好きにpuppeteerを動かせる
- フレキシブル環境個人で使うには高いからスタンダードのほうが良いかも
カスタムコンテナを動かすための設定
下記のチュートリアルに従いapp.yamlを編集する。カスタムランタイムをフレキシブル環境下で動かすよ!という設定をしているだけ。
runtime: custom env: flex
Chrome入りコンテナを作る
puppeteerの公式チュートリアルでは親切にDockerで動かすためのDockerFileを公開してくれている。これをGAE用に微修正してあげればOK.
# puppeteerのチュートリアルで公開されているDockerfileをGAE用に修正
# (修正)ベースイメージをgae用のものに変更
# FROM node:12-slim
FROM gcr.io/google-appengine/nodejs
# Install latest chrome dev package and fonts to support major charsets (Chinese, Japanese, Arabic, Hebrew, Thai and a few others)
# Note: this installs the necessary libs to make the bundled version of Chromium that Puppeteer
# installs, work.
RUN apt-get update \
&& apt-get install -y wget gnupg \
&& wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - \
&& sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' \
&& apt-get update \
&& apt-get install -y google-chrome-stable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf libxss1 \
--no-install-recommends \
&& rm -rf /var/lib/apt/lists/*
# If running Docker >= 1.13.0 use docker run's --init arg to reap zombie processes, otherwise
# uncomment the following lines to have `dumb-init` as PID 1
# ADD https://github.com/Yelp/dumb-init/releases/download/v1.2.2/dumb-init_1.2.2_x86_64 /usr/local/bin/dumb-init
# RUN chmod +x /usr/local/bin/dumb-init
# ENTRYPOINT ["dumb-init", "--"]
# Uncomment to skip the chromium download when installing puppeteer. If you do,
# you'll need to launch puppeteer with:
# browser.launch({executablePath: 'google-chrome-stable'})
# ENV PUPPETEER_SKIP_CHROMIUM_DOWNLOAD true
# Install puppeteer so it's available in the container.
RUN npm i puppeteer \
# Add user so we don't need --no-sandbox.
# same layer as npm install to keep re-chowned files from using up several hundred MBs more space
&& groupadd -r pptruser && useradd -r -g pptruser -G audio,video pptruser \
&& mkdir -p /home/pptruser/Downloads \
&& chown -R pptruser:pptruser /home/pptruser \
&& chown -R pptruser:pptruser /node_modules
# (追加)GAEではポート8080を公開する必要がある
EXPOSE 8080
# (追加)必要なソースコードとかのコピー
RUN mkdir /workdir
ADD . /workdir
WORKDIR /workdir
RUN npm install --only=production
# Run everything after as non-privileged user.
USER pptruser
# (修正)自前のアプリを動かすよう変更
# CMD ["google-chrome-stable"]
CMD ["npm", "start"]
デプロイする
一行で済んでめちゃ楽。
gcloud app deploy
やってることは本当に少し設定を変えてDockerFile作っただけ。必要なパッケージを好きにインストールできるのはフレキシブル環境の強みかも。
小学校低学年向け学習用プリント作成サービスprillをリリースしました
リリースして3週間くらい経っていますがせっかくリリースしたので記念に記事を書きました。全て応用情報技術者試験のせいでリリースに割くリソースが無かったせいです。(いい訳)
まだそっけないトップページですがサービスとして最低限のものが凝縮されています。
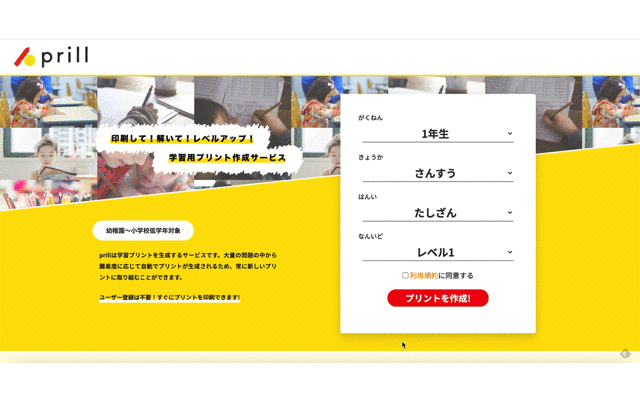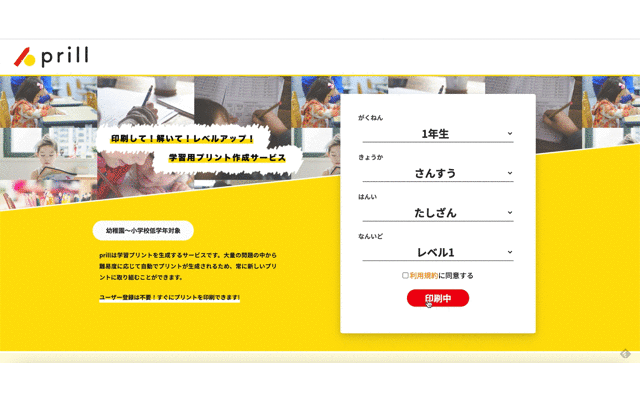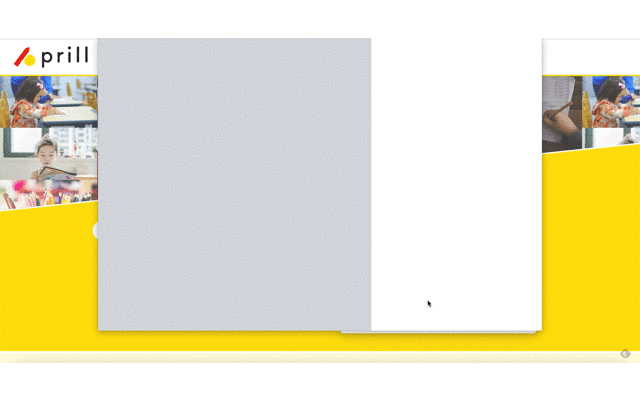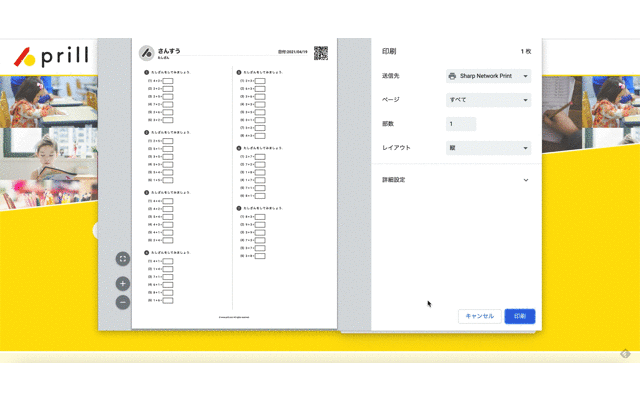
生成したいプリントの条件をセレクトボックスに入れるとそれに応じた問題をデータベースから探してプリントの形に整えてくれます。このサービス作った理由は↓に書いたのでこっちのブログではサービスを構成する技術的なことを書いてみようと思います。
TL; DR
- puppeteerは軽くてサーバー用途でも使いやすいのでHTML+CSSから画像を生成するサービス作りたならめちゃくちゃ便利だよ!
- GAEのフレキシブル環境はDockerコンテナを好きに動かせてデプロイも簡単なのでめちゃくちゃ便利だよ!(ただし多少高い)
- サービス使ってね!
プリント作成機能
メインの機能です。気合いれて作りました。
プリントをフロントエンドで生成 or バックエンドで生成の2択でサービス考案当初は少し悩みましたが、フロントで動かすとなるとブラウザなどのユーザーの環境によって左右されて画一的なプリントを提供できないのでは?ということで割とサックリとバックエンドで作ることに決めました。
なんとなくのサービス構成を考えて次は要件です。要件がふわっとしてる?個人開発なんてこんなんでいいんですよ。
- 隙間を埋めるようにちょうどいい感じでレイアウトしたい
- 子供が解いてて楽しいデザインにしたい
- あとからデザインの修正が簡単にできるようにしたい
- 複数の異なる問題形式を同じように扱いたい
1は適切な配置を探索する感じで実現できると思うので一回あたりのレンダリングにかかる時間は短いほうがいいなぁ、デザインの修正が楽な方法となるとCSSとかでいい感じに描画できないかなぁ、4は設計しだいだなぁ、などと考えていて行き着いたのがヘッドレスブラウザを使った画像生成でした。
久々にヘッドレスブラウザについて調べてみると、ヘッドレスブラウザといったらPhantom JS!という時代が終わったことを知りました。じゃあSeleniumでヘッドレスChrome使ってみようかと調べると複数の接続を同時に処理するのは難しそう・・・と絶望していたところでpuppeteerという存在を知りました。
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
puppeteerはrendertron(サーバーサイドレンダリングのライブラリ)にも採用されているjavascriptライブラリなので、1つのChromeインスタンスで複数のリクエストをぱぱーっと捌くことが出来ます。もうこれ使うしかないじゃんと思って採用しました。
画像を生成する方法さえ決まってしまえばあとはゴリゴリコード書いていくだけでした。プリントを生成するざっくりとした流れは
puppeteerのレンダリングにかかる時間によっては2の処理時間が膨大なことになるかもしれないと考えていましたが適当な打ち切り条件を入れれば現実的な時間で動くようになりました。
本当は簡単な問題から難しい問題に変化するようにうまく調整したりしたかったですがリリース優先ということで最低限の機能に絞りました。今後の課題ということでそのうち片付けます。
サーバー
annt作ったanntはフロントエンドがメインのサービスなのでVue使ってひたすらにJSを作り込んでいく作業がメインでした。そのためサーバーサイドはFirebaseでファイル返して少しだけ認証周りを書くだけでも十分なサービスでしたが、一方今回作ったprillはサーバーサイドでゴリゴリプリントを作る必要があるのでサーバーレスではなくてもう少し自由度が高いほうがいいなーと思っていました。プリントの作成をpuppeteerでやりたいからheadless chrome好きに使えて管理は楽なやつという基準で探していくとGoogle App Engineがお手頃そうでGAEに決めました。
GAEにはスタンダード環境とフレキシブル環境があって、後者のフレキシブル環境は好きにDockerコンテナを動かせます。かつ一度環境整えちゃえばデプロイ周りも簡単にできるのでめちゃくちゃ便利です。フレキシブル環境でpuppeteer動かす方法はいつか記事にしようと思います。
ただフレキシブル環境は高いです。東京リージョンで最安の構成で動かしていますが月6000円くらいは飛んできます。社会人だから耐えられましたが学生なら死んでました。
DBは少しお高いですがCloud SQLを使っています。採用したのに深い理由は無く同じGoogleで管理に手間かけたくないと思ったからです。アクセス少ないから最低価格の構成でいいや!と割り切って使ってます。アクセスが欲しい(涙
最後に
見てくれよ俺の自慢のサービス!という記事でした。サービス作ったあとに記事書いてる時間が一番楽しいかもしれません。辛いのは維持。充実したコンテンツを提供できるよう頑張ります。
Javascriptでキーボードショートカットを実装する
anntにキーボードショートカットを実装したいと思って調べてみても、検索に引っかかるのはライブラリの使い方ばっかりであまり具体的な仕組みが見つからない。あまりブラックボックスなライブラリを使いたくないという気持ちと、この程度簡単に実装できるだろというイキリで更に調査を進めるとshortcut.jsという非常にシンプルなライブラリが見つかった。
www.openjs.com コンパクトにまとまっているので、内容を読み解いた上で使いやすいようにクラスとして実装し直した。 注意点としてshortcut.jsはブラウザのバグやIEにも対応しているが、シンプルさを優先して今回の実装では省いている。
前提知識
キーボードに限らずブラウザのイベントは要素にaddEventListenerを登録することで監視することができる。キーボードのイベントとしてkeydown、keyupが定義されていて、keydownはその名の通りキーが押し込まれたときに発生するイベント、keyupはキーを離したときに発生するイベントとなっている。今回はkeydownイベントを監視することで、予め登録されたショートカットが押されたかを判断している。
keydownやkeyupのリスナーを登録しておくと、登録したコールバック関数にKeyboard Eventというオブジェクトが渡される。keyプロパティやcodeプロパティでどのキーが押されたかを確認できる。keyもcodeプロパティも押されたキーを取得するプロパティだが、両者には明確に違いがあるので使用する際にはキーボード: keydown と keyupを確認するのが良い。
Ctrlキー、Altキー、Cmdキーが押されているかどうかはctrlKey、altKey、metaKeyプロパティで取得できる。keyプロパティで押されたボタンを、ctrlKeyなどでコントロールキーを始めとしたキーが押されているかどうかを判断できるので、これでキーボードショートカットを実装できる。
| プロパティ名 | 概要 |
|---|---|
| key | 押されたキーの文字を表す |
| code | キーボードのレイアウトに依存しない押されたキーの位置を表すコードを表す |
| ctrlKey | Ctrlキーが押されているか |
| altKey | Altキーが押されているか |
| metaKey | Cmdキーが押されているか |
参考資料
ブラウザイベントの紹介
KeyboardEvent - Web APIs | MDN
プログラムの概要
ShortcutController
ショートカットを管理するメインのクラス。registerShortcutでキーバインドと関数を登録した状態で、handleメソッドをaddEventListenerで登録すればショートカットが使えるようになる。registerShortcutメソッドは使いやすいようにCtrl+Sのように'+'区切りでキーバインドを登録できるようにしてある。handleメソッドでは登録されているShortcutObject(次項参照)のigniteメソッドを一つづつ呼び出していく。
ShortcutObject
一つのショートカットを管理するためのホルダークラス。igniteメソッドは入力されたキーの情報を引数に取って、ショートカットの条件に合致した場合にのみ登録された関数を実行する。
プログラムの実装
const ALLOWED_KEY = ['backspace', 'esc', 'escape', 'tab', 'space', 'return'] /** * 使用可能なコードか判定を行う. * 1文字の英字かALLOWED_KEYに含まれる特殊文字のみが登録可能です. * https://developer.mozilla.org/en-US/docs/Web/API/KeyboardEvent/key/Key_Values * 入力は小文字である必要があります * @param {String} code */ function allowedCode(code) { if (code.length === 1 && code.match(/[a-z]/i)) { // 長さが1 return true; } return ALLOWED_KEY.includes(code); } /** * 1つのショートカットを表現するオブジェクト */ class ShortcutObject { /** * コンストラクタ * @param {*} char: ショートカットとして使用する英字1文字 * @param {*} ctrl: コントロールボタンと同時に押す必要があるか * @param {*} meta: (Mac用): コマンドボタンと同時に押す必要があるか。 * @param {*} propagate: Eventを伝播させるか。 * @param {*} func: ショートカットが押されたときに実行する関数 */ constructor(char, ctrl, meta, propagate, func) { this.char = char; this.ctrl = ctrl; this.meta = meta; this.propagate = propagate; this.func = func; } /** * 条件に合致したか判定して、合致した場合のみ登録された関数を実行 * @param {String} char * @param {Boolean} ctrl * @param {Boolean} meta */ ignite(event, char, ctrl, meta) { if (char === this.char && ctrl === this.ctrl && meta === this.meta) { this.func(); if (!this.propagate) { event.preventDefault(); if (event.stopPropagation()) { event.stopPropagation(); } } } } } class ShortcutController { /** * コンストラクタ */ constructor() { this.shortcutList = []; } /** * ショートカットを登録する * @param {String} keybind: キーバインドを表す文字列, 例) Ctrl+S * @param {Function} callback: ショートカットが押されたときに呼び出す関数 * @param {Boolean} propagate : デフォルトのショートカットを呼び出すか。 */ registerShortcut(keybind, callback, propagate=false) { // + で区切ってすべて小文字のリストに // 例)Ctrl+A => [ctrl, a] const keys = keybind.split('+').map((s) => s.toLowerCase()); // キーバインドをパース let needCtrl = false; let needMeta = false; let char = null; keys.forEach((k) => { if (k === 'ctrl') { needCtrl = true; } else if (k === 'meta') { needMeta = true; } else if(allowedCode(k)){ char = k; } else { // 使用できないキーが含まれている throw new Error('Irrelvalent Shortcut'); } }); if (char === null) { throw new Error('Irrelvalent Shortcut'); } // ショートカットをリストに追加する const shortcut = new ShortcutObject(char, needCtrl, needMeta, propagate, callback); this.shortcutList.push(shortcut); } /** * addEventListenerようのハンドラー * * @param {Event} event */ handle(event) { const ctrl = event.ctrlKey; const meta = event.metaKey; const char = event.key.toLowerCase(); this.shortcutList.forEach((shortcut) => { shortcut.ignite(event, char, ctrl, meta); }); } } export default { ShortcutController, }
割と短く実装出来た。流し読みして見切り発射の実装なので何か漏れがあるかも。上でも書いたがshortcut.jsではブラウザ周りのバグなどにも対応してそうなので、特段の主義主張が無いのであればこちらを使うのがおすすめです。
個人開発サービスの記事周りをWordpressに切り出した。
タイトルの日本語が怪しい気がします。コツコツ開発しているanntの話です。
anntはFirebaseで動いていて基本的には静的なページで動いていたので、チュートリアルなどの記事を書くときも直接htmlタグ付けしていくという苦行をしていました。最近さすがに当時の自分は何を考えてこんなの作ったんだ?と思い始めたので記事や頻繁に編集する部分をWordpressに切り出しました。
利用する環境
とにかく楽に環境を整えたかったのでWordpressはGCP Market Placeで立てようと決めていました。GCP Market PlaceでWordpressを立てるのは本当に楽でクリックしていくだけで新しいインスタンスでWordpressが動いている状態になります。Google様々です。
全体の構成として当初はannt.aiに来た/post以下のリクエストだけをうまくWordpressに回せないか検討していました。色々方法を模索しましたがFirebaseはあくまで静的ファイルのホスティングやサーバレスでシンプルなAPIを実現するためのサービスです。来たリクエストの一部を別のサーバーに流すようなロードバランサ的な機能は簡単には実現できなさそうでした。
Firebaseの前に別のロードバランサ挟んでリクエスト割り振ればいいのでは?と思いもしましたが更に課金するのは嫌だなという気持ちになりました。嘘です。本当は面倒くさかっただけです。なので更に別の方法を模索しました。
最終的な構成
結論としてサブドメイン取ってサービス本体とは完全に切り離して運用することにしました。本体のサービスとは完全に分かれているので管理が楽です。何かに負けている気がしますが気にしません。大事なのはスピードです。
GCP Market Placeで作成されたインスタンスにはIPアドレスが振り分けられますがデフォルトだとエフェメラルという設定になっていて、インスタンスを起動停止するたびに別のIPに変わってしまう可能性があります。最終的にいい感じにインスタンスに対してサブドメインを設定するには、
こんな感じの作業をやっていく必要があります。
静的IPアドレスの設定
調べるとたくさん記事が出てきます。 Google Cloud Platformの外部IPアドレスのURLから静的アドレスに変更できます。 条件によっては課金されるので注意してください。
GCPで作成したWordpressの静的IPアドレスの設定方法 - Qiita
ネームサーバーの設定変更
利用しているレジストラ(お名前.comやGoogleドメイン等)によってやり方は違うと思います。 やることとしては新しいサブドメインと作成した静的アドレスを対応付けるAレコードを追加するだけで大丈夫なはずです。
TLS(SSL)の設定
今はTLSが正しい表現になるのでしょうか。初めてTLSの設定を行いましたがCertbotというツールを使えばLet's encryptの証明書を簡単に手に入れられます。
GCP Market PlaceでWordpressを立ち上げるとおそらくDebian+Apacheで動いていると思います(今後変わる可能性もあるので注意してください)。 自分はaptでcertbotをインストールしましたが(うろ覚え)CertbotのトップページにOS+サーバーを指定すれば導入方法を親切に教えてくれるので、それに従うのが一番確実かと思います。Wordpress+GCP Market Place + TLSでググると何個か日本語の資料も引っかかりますが古いのかCertbotが正しく動作しなかったので素直に公式に従うのがいいと思います。 certbot.eff.org
そんなこんなで最後には無事Wordpress環境を整えることが出来ました。本当に楽にセットアップできるので、雑にブログ or それに類する記事執筆システム作るにはおすすめです。
↓ 作ったもの。